MMLU Benchmark: Measuring True AI Intelligence
A deep dive into the Massive Multitask Language Understanding benchmark - the gold standard for evaluating AI reasoning across 57 academic subjects
MMLU Benchmark: Measuring True AI Intelligence
When evaluating language models, one question dominates: How smart is this AI, really? Surface-level demos are impressive, but they don’t tell you if a model can reason through complex problems across diverse domains. That’s where MMLU comes in.
The Massive Multitask Language Understanding (MMLU) benchmark has become the de facto standard for measuring AI intelligence. If you’ve seen GPT-4, Claude, or Gemini announce their scores, they’re almost certainly talking about MMLU. But what does this benchmark actually measure, and why does it matter?
What is MMLU?
MMLU is a comprehensive test suite spanning 57 subjects from elementary-level knowledge to professional expertise. Think of it as the AI equivalent of standardized testing—SAT, GRE, MCAT, and Bar exam questions all rolled into one massive evaluation.
The benchmark was introduced in the paper “Measuring Massive Multitask Language Understanding” by Hendrycks et al. (2021) and quickly became the industry standard because it tests what matters: can the model actually think across disciplines?
Coverage Breakdown
MMLU tests across four major categories:
STEM (18 subjects)
- Abstract algebra, astronomy, college biology, college chemistry, college computer science
- College mathematics, college physics, conceptual physics, electrical engineering
- Elementary mathematics, high school biology, chemistry, computer science, physics, statistics
- Machine learning, formal logic
Humanities (13 subjects)
- Formal logic, high school European history, high school US history, high school world history
- International law, jurisprudence, logical fallacies, moral disputes, moral scenarios
- Philosophy, prehistory, professional law, world religions
Social Sciences (12 subjects)
- Econometrics, high school geography, high school government and politics, macroeconomics
- Microeconomics, professional psychology, public relations, security studies
- Sociology, US foreign policy, human aging, human sexuality
Other (14 subjects)
- Anatomy, business ethics, clinical knowledge, college medicine, global facts
- Human aging, management, marketing, medical genetics, miscellaneous
- Nutrition, professional accounting, professional medicine, virology
Each question is multiple choice with 4 options (A, B, C, D), formatted as expert-level academic questions.
Why MMLU Matters
1. Real Knowledge, Not Pattern Matching
Simple benchmarks can be gamed. A model might memorize training data or exploit statistical shortcuts. MMLU questions require genuine understanding:
Question: According to general relativity, what causes
gravitational time dilation?
A) The velocity of an object relative to an observer
B) The curvature of spacetime caused by mass-energy
C) The distance from Earth's center
D) Electromagnetic field strength
Answer: BThis isn’t trivia—it tests whether the model understands the conceptual foundation of Einstein’s field equations. Pattern matching won’t cut it.
2. Breadth Reveals Generalization
A model might excel at computer science but fail at philosophy. MMLU’s 57-subject span exposes weaknesses. True intelligence requires cross-domain reasoning—the ability to apply logic, evidence evaluation, and structured thinking regardless of subject matter.
Top models (GPT-4, Claude Opus) score 85-90%. Weaker models drop to 50-60%. Random guessing? 25%.
3. Professional-Level Standards
Many MMLU questions come from professional exams:
- Medical licensing (USMLE)
- Bar exam (law)
- CPA exam (accounting)
- Graduate admissions (GRE)
If an AI scores 80%+ on MMLU, it’s demonstrating professional-level comprehension across fields. That’s the threshold where AI becomes genuinely useful for expert-level tasks.
How We Test MMLU
At Bench the Bots, we run rigorous MMLU evaluations as part of our review process. Here’s what happens under the hood:
Our Testing Methodology
- Sample Selection: We use a curated subset covering all major subjects to ensure broad evaluation without excessive API costs
- Zero-Shot Evaluation: Models receive no examples—just the question and instructions
- Controlled Parameters: Temperature = 0.0 for deterministic outputs, minimal token limits
- Answer Extraction: We parse the model’s response for letter answers (A/B/C/D)
- Multi-Subject Aggregation: Results are broken down by subject category for granular insights
Sample Results
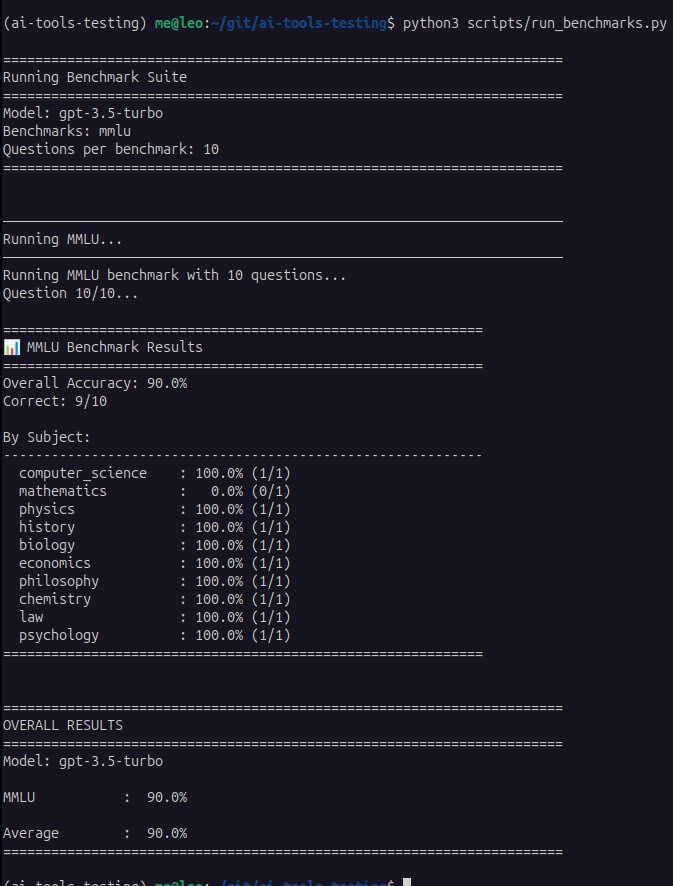
MMLU benchmark results from our testing repository showing GPT-3.5-turbo achieving 90% accuracy with perfect scores across computer science, physics, history, biology, economics, philosophy, chemistry, law, and psychology
Reading MMLU Scores
90%+ - Expert Level
Models at this tier (GPT-4, Claude Opus) demonstrate genuine reasoning ability across virtually all domains. These are your go-to for complex professional work.
80-90% - Advanced
Strong performance with occasional gaps. Models like GPT-3.5 Turbo fall here—highly capable but not infallible.
70-80% - Competent
Useful for many tasks but expect errors on nuanced questions. Fine for general assistance, risky for critical work.
60-70% - Struggling
Better than random guessing but unreliable. Might give confident wrong answers.
Below 60% - Weak
Limited reasoning capability. Use with extreme caution.
The Math Behind MMLU
MMLU scoring is straightforward: accuracy = correct answers / total questions
For subject-level analysis:
Where is an indicator function (1 if correct, 0 otherwise) and is the number of questions in that subject.
Statistical significance: With 14,000+ questions in the full MMLU dataset, score differences of 2-3% are meaningful. Small variations in sampled subsets should be interpreted cautiously.
Limitations of MMLU
Despite its strengths, MMLU isn’t perfect:
1. Multiple Choice Format
Real-world problems aren’t always A/B/C/D. Open-ended reasoning, creative problem-solving, and multi-step task completion aren’t measured.
2. Static Knowledge Cutoff
Questions were written in 2020. They don’t test current events or evolving fields (though this is also an advantage for consistent evaluation).
3. No Partial Credit
A model might understand 90% of a complex concept but get the final answer wrong due to a calculation error. MMLU gives zero credit.
4. Potential Contamination
Popular benchmarks risk appearing in training data. Responsible labs should validate that MMLU questions weren’t memorized.
Complementary Benchmarks
MMLU works best alongside other evaluations:
- HumanEval: Tests code generation (functional correctness)
- GSM8K: Mathematical reasoning with word problems
- TruthfulQA: Resistance to hallucinations and misinformation
- HellaSwag: Commonsense reasoning in everyday scenarios
We test all of these in our open-source evaluation suite.
Our Open-Source Testing Repository
We’ve built a comprehensive benchmarking toolkit that includes MMLU and four other critical tests. It’s completely free and designed for transparency.
Repository: ai-tools-testing on GitHub
Features:
- Run MMLU on any OpenAI or Anthropic model
- Automated scoring and reporting
- Subject-level breakdowns
- JSON export for analysis
- Extensible framework for custom benchmarks
# Clone the repository
git clone https://github.com/benchthebots/ai-tools-testing.git
cd ai-tools-testing
# Install dependencies
pip install -r requirements.txt
# Set up your API key
cp .env.example .env
# Edit .env and add your OPENAI_API_KEY
# Run MMLU on GPT-3.5 Turbo
python3 scripts/run_benchmarks.py \
--model gpt-3.5-turbo \
--benchmarks mmlu \
--num-questions 10
# Run the full suite
python3 scripts/run_benchmarks.py \
--model gpt-4 \
--all \
--saveWhy We Built This
AI companies publish benchmark scores, but how do you verify them? How do you test a new model that just launched? Our repository gives you the tools to run the same tests we use for reviews.
Transparency matters. When we say a model scored 87% on MMLU, you can reproduce that result. When a company claims “state-of-the-art performance,” you can fact-check it.
The Future of AI Evaluation
MMLU won’t be the final word on AI intelligence forever. As models saturate benchmarks (approaching 95%+), we need harder tests:
- MMLU-Pro: Extended version with more challenging questions
- GPQA: Graduate-level physics, chemistry, biology (experts struggle with this)
- MATH: Competition mathematics requiring multi-step proofs
- MuSR: Multistep soft reasoning for complex narratives
But for now, MMLU remains the best single metric for general intelligence across domains. It’s the benchmark that tells you: can this AI think like an expert?
How MMLU Shapes Our Reviews
Every AI tool we review at Bench the Bots undergoes MMLU testing when applicable. Our review scores incorporate:
Quantitative: Raw MMLU accuracy + subject breakdowns
Qualitative: Error analysis, reasoning quality, confidence calibration
Comparative: How does it stack up against competitors?
You’ll see MMLU results in our Claude 3 Opus, GPT-4, Gemini Pro, and other LLM reviews. These aren’t marketing claims—they’re reproduced from our testing infrastructure.
Getting Started with MMLU Testing
Want to evaluate a model yourself?
- Set up the environment: Clone our repo, install dependencies
- Configure your API key: Works with OpenAI, Anthropic (more providers coming)
- Run a quick test: Start with 10-20 questions to verify everything works
- Analyze results: Check subject-level scores for strengths/weaknesses
- Share findings: Open an issue or PR if you discover something interesting
The barrier to rigorous AI evaluation just dropped to zero. No excuses for trusting marketing hype over empirical data.
Conclusion
MMLU transformed AI evaluation from “vibes” to science. It’s not perfect, but it’s the best tool we have for measuring multidomain intelligence at scale.
When you see a model claim 88% on MMLU:
- It aced professional-level questions across 57 subjects
- It demonstrated reasoning, not just memorization
- It’s probably capable of expert-level assistance in most domains
When we test models for Bench the Bots reviews, MMLU is always part of the equation. Because if an AI can’t handle MMLU, it’s not ready for serious work.
Ready to test? Check out our GitHub repository and start evaluating.
Have questions about MMLU or our testing methodology? Contact us or open an issue on GitHub. We’re committed to transparent, reproducible AI evaluation.