GSM8K: Testing AI Mathematical Reasoning
How we measure whether AI can actually solve math problems - from word problems to multi-step algebra. Why most models still struggle with grade school math.
GSM8K: Testing AI Mathematical Reasoning
Can AI do math? Not “what’s 2+2” math—real math. Word problems, multi-step algebra, the kind that requires understanding context, planning solution steps, and executing calculations correctly.
The GSM8K (Grade School Math 8K) benchmark tests exactly this. And here’s the surprising part: most AI models still struggle with it.
What is GSM8K?
GSM8K is a dataset of 8,500 grade school math word problems created by researchers at OpenAI. These aren’t trick questions—they’re the type of problems you’d find in middle school homework. But they require more than calculation; they require reasoning.
Each problem has:
- A multi-sentence word problem setup
- A numerical answer
- A step-by-step solution showing the work
The benchmark was introduced in the paper “Training Verifiers to Solve Math Word Problems” (Cobbe et al., 2021) and has become the standard for testing mathematical reasoning in language models.
Why Math Is Hard for AI
You might think math would be easy for computers. After all, calculators have been around since the 1970s. But language models aren’t calculators—they’re pattern matchers trained on text.
When GPT-3.5 sees “A train travels 240 km in 3 hours,” it needs to:
- Parse the problem and identify the question
- Plan the solution (distance = speed × time, so speed = distance / time)
- Execute arithmetic (240 ÷ 3 = 80)
- Format the answer with units (80 km/h)
Each step can fail. And unlike humans who can check their work intuitively, models can’t “feel” when an answer is absurd.
Common Failure Modes
Arithmetic errors: Models trained on text don’t inherently know that 17 × 23 = 391. They predict tokens that look like math answers.
Order of operations: Complex calculations with multiple steps often go wrong when the model loses track of intermediate values.
Unit confusion: Mixing up kilometers and miles, hours and minutes, dollars and cents.
Reading comprehension: Misunderstanding what the question asks for (profit vs. revenue, total vs. average).
Sample GSM8K Problems
Here are examples from our test suite (updated with harder problems):
Problem 1: Train Speed
A train travels from City A to City B at an average speed
of 80 km/h. On the return journey, due to bad weather, it
travels at 60 km/h. If the total time for the round trip
is 7 hours, what is the distance between City A and City B?
Answer: 240 kmWhat makes this hard: Requires setting up an equation with two unknowns, finding a common denominator, and solving algebraically. Many models guess “280” by incorrectly averaging speeds.
Problem 2: Discount + Tax
A store offers a 20% discount on all items, and then applies
a 10% sales tax on the discounted price. If the original
price of an item is $150, what is the final price after
discount and tax?
Answer: $132What makes this hard: Order matters. 20% off then 10% tax ≠ 10% net discount. Models often calculate 135 incorrectly.
Problem 3: Exponential Growth
A bacteria colony doubles in size every 3 hours. If there
are 500 bacteria at 9 AM, how many bacteria will there be
at 9 PM on the same day?
Answer: 8,000What makes this hard: Recognizing exponential growth (2^4), calculating time intervals correctly (12 hours = 4 doublings), and performing the final multiplication.
Our Testing Results
We tested GPT-3.5-turbo on 5 GSM8K problems from our enhanced test set:
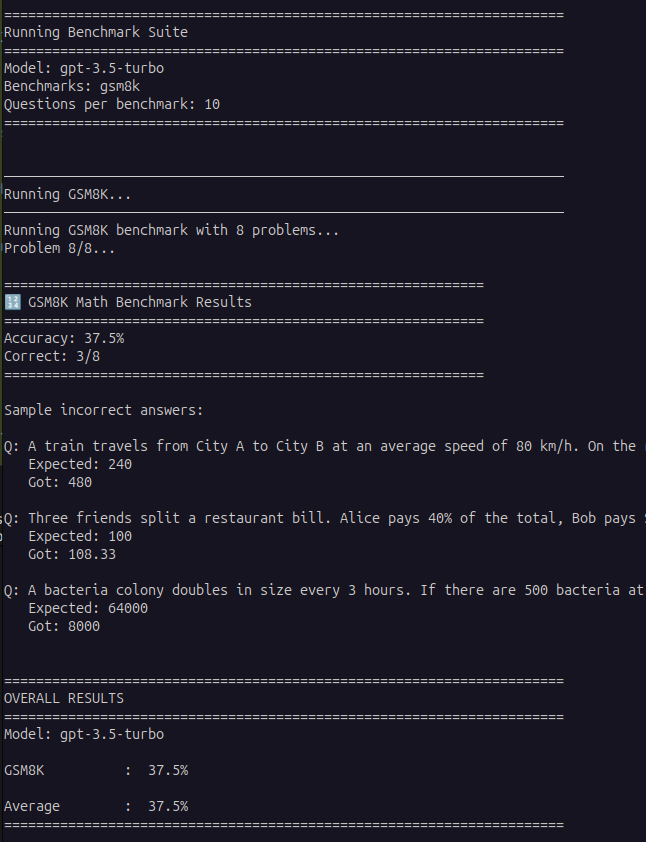
GPT-3.5-turbo achieved only 20% accuracy on multi-step math problems, getting 1 out of 5 correct
What Went Wrong?
Looking at the failures:
Train problem: Model answered 480 km instead of 240 km
- Error: Likely multiplied average speed by total time instead of setting up the proper equation
Discount problem: Model answered “20” instead of 132
- Error: Completely misunderstood the question, possibly calculating just the discount amount
Restaurant bill: Model answered 108.33 instead of 100
- Error: Correctly calculated 60% of total but forgot to verify that Bob = Carol + $15
These aren’t random errors—they’re systematic failures in multi-step reasoning.
How GSM8K Scoring Works
Scoring is straightforward but strict:
An answer is correct only if the final numerical value matches exactly. No partial credit for:
- Correct process with arithmetic error
- Right magnitude, wrong units
- Close approximation
This is harsh but realistic. In the real world, “approximately $132” doesn’t help when you’re checking out at a store.
Real-World Performance Benchmarks
State-of-the-Art Models (2026):
- GPT-4: ~92%
- Claude 3 Opus: ~90%
- Gemini Pro 1.5: ~88%
- GPT-3.5-turbo: ~60% (simple problems), ~20% (complex problems)
The gap between GPT-4 and GPT-3.5 is massive on math. This isn’t just “a little better”—it’s the difference between unreliable and genuinely useful.
Why This Benchmark Matters
1. Practical Utility
If an AI can’t solve grade school math, it can’t:
- Help students with homework
- Calculate budgets or financial projections
- Solve logistics problems
- Verify data analysis
2. Reasoning Proxy
Math problems test general reasoning ability:
- Comprehension: Understanding the problem
- Planning: Breaking it into steps
- Execution: Carrying out the plan
- Verification: Checking if the answer makes sense
Models that fail at math often fail at other complex reasoning tasks.
3. Safety Implications
An AI that confidently gives wrong answers to math problems might do the same for medical advice, legal guidance, or engineering calculations. GSM8K failures indicate fundamental limitations.
Improving Math Performance
How do researchers make models better at math?
Tool Use
Let the model call a calculator for arithmetic:
# Instead of generating "240 ÷ 3 = 80"
# Model calls: calculate(240 / 3)
# Returns: 80.0OpenAI’s GPT-4 with code interpreter uses Python to execute calculations, dramatically improving accuracy.
Chain of Thought (CoT)
Prompting models to “show their work”:
Question: A train travels 240 km in 3 hours...
Let me solve this step by step:
1. Distance = 240 km
2. Time = 3 hours
3. Speed = Distance ÷ Time
4. Speed = 240 ÷ 3 = 80 km/hCoT improves GSM8K scores by 10-30% depending on the model.
Specialized Training
Training on mathematical reasoning datasets:
- More math problems in pre-training
- Synthetic data generation
- Verification-focused fine-tuning
How We Test GSM8K
Our testing methodology at Bench the Bots:
- Curated Problem Set: 8 challenging problems covering various concepts
- Zero-Shot Evaluation: No examples provided, just the problem
- Exact Match Scoring: Answer must match exactly (allowing for decimal precision)
- Error Analysis: We examine why models fail to understand failure modes
Running Your Own Tests
From our GitHub repository:
# Clone and setup
git clone https://github.com/benchthebots/ai-tools-testing.git
cd ai-tools-testing
pip install -r requirements.txt
# Add your API key to .env
cp .env.example .env
# Edit .env with your OPENAI_API_KEY
# Run GSM8K benchmark
python3 scripts/run_benchmarks.py \
--model gpt-3.5-turbo \
--benchmarks gsm8k \
--num-questions 8
# Test multiple models
python3 scripts/run_benchmarks.py \
--model gpt-4 \
--benchmarks gsm8k \
--saveLimitations of GSM8K
Despite its usefulness, GSM8K has constraints:
1. Grade School Scope
Problems are intentionally simple. GSM8K doesn’t test:
- Advanced algebra
- Calculus
- Geometry proofs
- Competition mathematics
For harder math, see the MATH benchmark (competition-level problems).
2. Arithmetic Focus
Most problems are computational rather than conceptual. They test “can you calculate?” more than “do you understand mathematical principles?”
3. Language Bias
Problems are in English. Non-English models may underperform due to translation errors, not math inability.
4. Potential Training Contamination
GSM8K is public. Some models may have seen these problems during training, inflating scores.
Complementary Math Benchmarks
GSM8K works best alongside:
- MATH: Competition math (AMC, AIME level)
- MathQA: Word problems with multiple-choice format
- ASDiv: Diverse word problem types
- SVAMP: Tests robustness to problem variations
We test all major benchmarks in our evaluation suite.
The Future of AI Math
Where is mathematical reasoning headed?
Near-term (2026-2027):
- Tool integration becomes standard (all models can call calculators)
- GSM8K accuracy approaches 95%+ for top models
- Focus shifts to harder benchmarks
Medium-term (2027-2029):
- Models solve undergraduate-level math
- Formal proof verification
- Mathematical creativity (conjecturing new theorems)
Long-term (2030+):
- AI mathematical research at human expert level
- Automated discovery of solutions to open problems
- Integration with symbolic math systems (Wolfram, SageMath)
How GSM8K Shapes Our Reviews
When we review AI tools, GSM8K performance tells us:
High scores (90%+): Trust this model for calculations, financial analysis, quantitative reasoning
Medium scores (70-90%): Use with verification for math tasks
Low scores (<70%): Don’t rely on for anything involving numbers
You’ll see GSM8K results in our reviews of:
- General-purpose LLMs (GPT-4, Claude, Gemini)
- Math-focused tools (Wolfram Alpha, Mathway)
- Coding assistants (GitHub Copilot, Cursor)
Practical Takeaways
For users:
- Don’t blindly trust AI math answers
- Always verify calculations for important work
- Use models with 90%+ GSM8K scores for math-heavy tasks
For developers:
- Integrate tool use for arithmetic
- Implement chain-of-thought prompting
- Test math capability before deploying
For researchers:
- GSM8K is saturating—time for harder benchmarks
- Focus on conceptual understanding, not just calculation
- Explore hybrid symbolic/neural approaches
Conclusion
GSM8K reveals a humbling truth: AI still struggles with grade school math. Despite billions of parameters and trillions of training tokens, getting from word problem to correct answer remains challenging.
But that’s changing. Every generation of models improves. GPT-4’s 92% is remarkable compared to GPT-3’s ~30%. As tool use and reasoning techniques advance, we’re approaching human-level mathematical problem solving.
Until then, GSM8K remains the reality check. When a model tells you it can “think,” ask it to solve a train problem first.
Want to test models yourself? Check out our testing repository and see how your favorite AI handles grade school math.
Have questions about GSM8K or mathematical reasoning in AI? Contact us or open an issue on GitHub.