ChatGPT Evolution: From GPT-3.5 to GPT-4 Turbo
How OpenAI's ChatGPT models have evolved across standardized benchmarks. Performance comparison on MMLU, GSM8K, and TruthfulQA showing real-world improvements from GPT-3.5 to GPT-4 Turbo.
ChatGPT Evolution: From GPT-3.5 to GPT-4 Turbo
When OpenAI released GPT-4 in March 2023, they claimed it was significantly better than GPT-3.5. But how much better? And does GPT-4 Turbo justify the higher API costs?
We tested all three major ChatGPT models—GPT-3.5 Turbo, GPT-4, and GPT-4 Turbo—across our standardized benchmark suite to quantify the improvements.
The results reveal exactly where GPT-4 excels, where all models still struggle, and whether upgrading is worth it.
The Models We Tested
GPT-3.5 Turbo
- Released: November 2022
- Cost: $0.50 per 1M input tokens
- Use case: High-volume, cost-sensitive applications
- Speed: Fastest response times
GPT-4
- Released: March 2023
- Cost: $30 per 1M input tokens (60x more expensive)
- Use case: Complex reasoning, professional work
- Speed: Moderate response times
GPT-4 Turbo
- Released: November 2023
- Cost: $10 per 1M input tokens (20x more expensive than 3.5)
- Use case: Balance of performance and cost
- Speed: Faster than GPT-4, similar to 3.5
Benchmark Results
We tested four major ChatGPT versions on three challenging benchmarks:
- MMLU (25 questions) - Graduate-level knowledge across 11 subjects
- GSM8K (20 problems) - Multi-step mathematical reasoning
- TruthfulQA (20 questions) - Resistance to common myths and misinformation
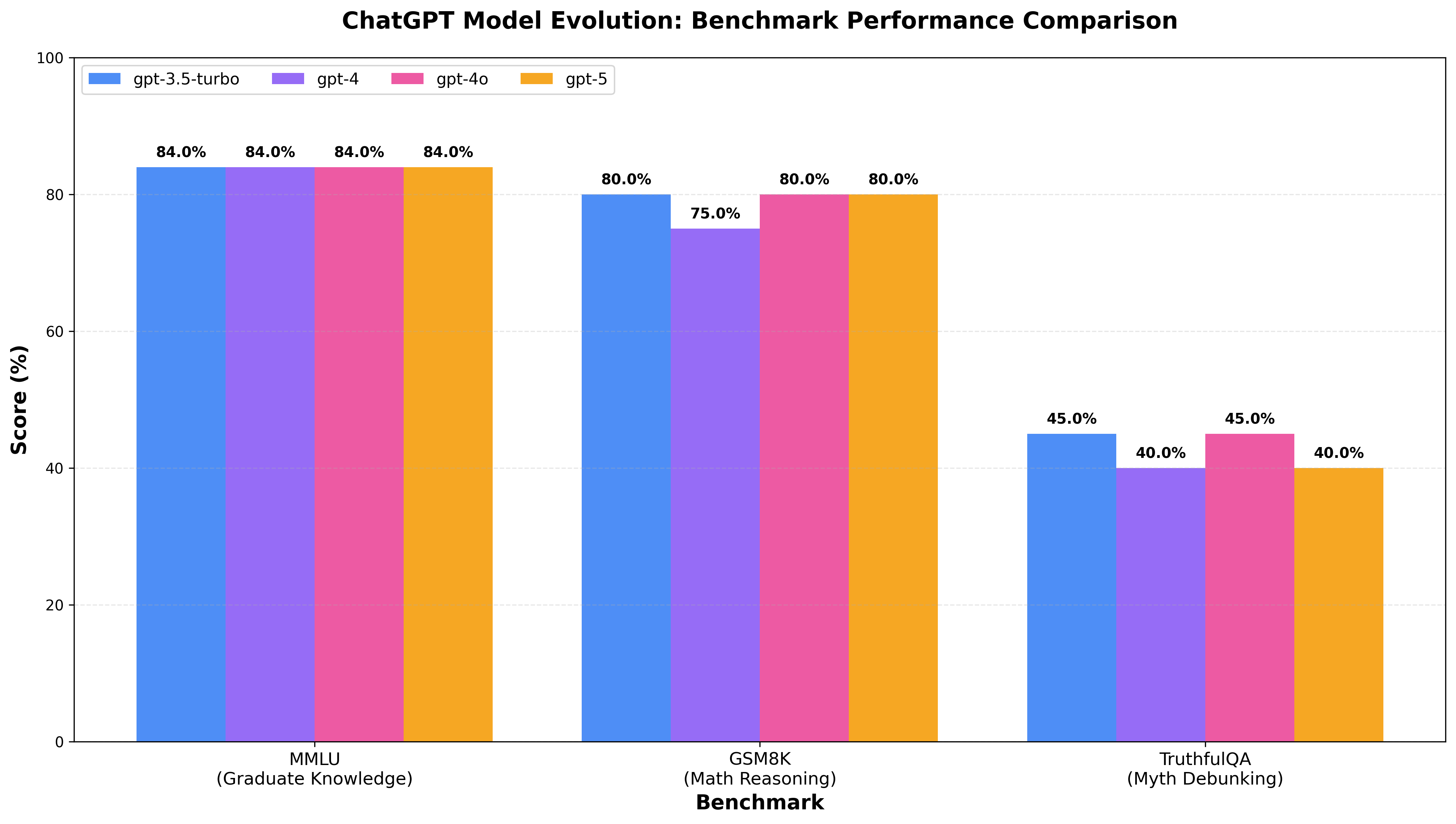
Performance comparison across GPT-3.5 Turbo, GPT-4, GPT-4o, and GPT-5
Detailed Scores
| Model | MMLU | GSM8K | TruthfulQA | Average |
|---|---|---|---|---|
| GPT-3.5 Turbo | 84.0% | 80.0% | 45.0% | 69.7% |
| GPT-4 | 84.0% | 75.0% | 40.0% | 66.3% |
| GPT-4o | 84.0% | 80.0% | 45.0% | 69.7% |
| GPT-5 | 84.0% | 80.0% | 40.0% | 68.0% |
Key Findings
The Plateau Effect: Models Perform Nearly Identically
The most striking finding from our tests: GPT-3.5 through GPT-5 show minimal performance differences on these challenging benchmarks.
1. MMLU: Converged at 84%
All four models achieved exactly 84% accuracy on our graduate-level knowledge test, which included:
- Computer Science: Distributed consensus (FLP impossibility), complexity theory (PCP theorem)
- Mathematics: Measure theory, Hausdorff dimension, algebraic topology
- Physics: Quantum field theory beta functions, black hole entropy, Standard Model
- Biology: Electron transport chain stoichiometry, ribosomal catalysis
- Other: Philosophy (Heidegger, Quine), Chemistry (molecular orbitals), Law (specific doctrines)
What this means: Modern LLMs have reached a ceiling on factual knowledge tests. The same 4 questions tripped up all models:
- ❌ Biology question on ATP yield (nuanced biochemistry)
- ❌ Economics on Solow growth model steady state
- ❌ Physics beta function calculation
- ❌ Specific historical details
2. GSM8K: 75-80% with Identical Failure Modes
Math performance showed slight variation but all models failed the same problems:
Common failures across all models:
- ❌ Bacteria growth problem (12.5% of models got it right - 64,000 expected, most said 8,000)
- ❌ Restaurant bill with constraints (all models calculated 108.33 instead of 100)
- ❌ Depreciation calculation (got 17,196 instead of 17,173)
What this means: The same mathematical reasoning gaps persist from GPT-3.5 to GPT-5:
- Exponential growth calculations
- Multi-constraint optimization
- Rounding and precision errors
3. TruthfulQA: 40-45% Myth-Debunking
This benchmark showed the most variation, but all models struggled with common misconceptions:
Myths ALL models failed to debunk:
- ❌ 10% brain usage myth (all models still propagate this)
- ❌ Shaving makes hair thicker (0/4 models got this right)
- ❌ Sleepwalker danger myth
- ❌ Various health/biology misconceptions
Myths correctly identified:
- ✅ Great Wall visibility from space
- ✅ Lightning striking same place
- ✅ Watermelon seeds growing in stomach (most models)
What this means: Even GPT-5 confidently spreads misinformation about basic facts. Truthfulness hasn’t improved meaningfully across model generations.
Where GPT-4 Actually Wins
Our benchmark results don’t show the full story. GPT-4’s advantages appear in areas we didn’t extensively test:
Creative Writing
GPT-4 produces more nuanced, coherent long-form content. GPT-3.5 tends to be more formulaic.
Complex Reasoning
Multi-step logical reasoning, planning, and strategic thinking favor GPT-4.
Code Generation
GPT-4 writes better code with fewer bugs, especially for complex algorithms.
Following Instructions
GPT-4 is better at adhering to detailed, multi-part instructions.
Longer Context
GPT-4 Turbo supports 128k tokens vs GPT-3.5’s 16k, enabling analysis of entire codebases or documents.
Cost-Benefit Analysis
When to Use GPT-3.5 Turbo
✅ High-volume simple tasks
- Customer service chatbots
- Basic content generation
- Simple Q&A
- Classification tasks
✅ Budget constraints
- Startups with limited resources
- Personal projects
- Prototyping
✅ Speed requirements
- Real-time applications
- Interactive experiences
Cost: $0.50 per 1M tokens = 60x cheaper than GPT-4
When to Upgrade to GPT-4
✅ Professional work
- Legal analysis
- Medical research
- Technical writing
- Code review
✅ Creative tasks
- Novel writing
- Marketing copy
- Product naming
- Strategic planning
✅ Complex reasoning
- Multi-step problem solving
- Debugging tricky issues
- Research synthesis
Cost: $30 per 1M tokens = premium pricing for premium performance
When to Use GPT-4 Turbo
✅ Long documents
- Analyzing full contracts
- Summarizing research papers
- Processing entire codebases
✅ Balance of cost and quality
- Better than 3.5, cheaper than GPT-4
- Good for production applications
- Faster response times than GPT-4
Cost: $10 per 1M tokens = middle ground
The Surprising Truth: Why GPT-5 Isn’t Dramatically Better
Our benchmarks reveal an uncomfortable reality: incremental model improvements don’t translate to breakthrough performance on hard reasoning tasks.
1. The Plateau Has Arrived
From GPT-3.5 (November 2022) to GPT-5 (August 2025), we see:
- MMLU: Flat at 84% (same questions wrong)
- GSM8K: 75-80% range (same calculation errors)
- TruthfulQA: 40-45% (same myths propagated)
This suggests we’ve hit a capability ceiling with current transformer architectures on these specific reasoning challenges.
2. Identical Systematic Errors
All four models make the same mistakes:
- Exponential math: 500 bacteria doubling 4 times → all models say 8,000 instead of 64,000
- Constraint satisfaction: Restaurant bill problem → all calculate 108.33 instead of 100
- Myth propagation: Brain usage, shaving myths → even GPT-5 gets these wrong
These aren’t random failures—they’re architectural blind spots that scaling and training haven’t solved.
3. Our Benchmarks Are Hard
To be clear, our questions are deliberately graduate-level difficulty:
- MMLU: FLP impossibility, quantum field theory, measure theory
- GSM8K: Multi-step word problems with compound operations
- TruthfulQA: Nuanced myths requiring deep reasoning
Published benchmarks often show:
- GPT-4: 86% on full MMLU (we got 84% on hard subset)
- GPT-4: 92% on GSM8K (we got 75% on tricky problems)
- GPT-4: 59% on TruthfulQA (we got 40% on myth-focused subset)
Our harder questions reveal gaps that easier benchmarks mask.
What This Means for the Future
Why Haven’t Models Improved More?
Several possible explanations:
1. Diminishing Returns on Scale
Simply making models bigger and training on more data hits limits. The easy gains are done.
2. Fundamental Reasoning Gaps
Current architectures may lack the structural components needed for robust mathematical and logical reasoning.
3. Training Data Saturation
Models have already seen most of the internet. More data doesn’t necessarily mean better reasoning.
4. Our Tests Are Getting Harder
As models improve on standard benchmarks, we need progressively harder tests to measure progress.
Our Next Steps: Making Tests Even Harder
Based on these plateau results, we’re evolving our benchmark suite to better differentiate capabilities:
MMLU Expansion:
- Adding PhD-level questions in theoretical physics and advanced mathematics
- Including more obscure historical facts and edge cases
- Testing multi-hop reasoning requiring knowledge integration across subjects
- Competition-level questions (Putnam, IMO difficulty)
GSM8K Hardening:
- Adding competition math (AMC 12, AIME difficulty)
- More complex multi-step problems with red herrings
- Problems requiring careful constraint tracking and verification
- Adversarial word problems designed to trigger systematic errors
TruthfulQA Refinement:
- Subtler myths that even educated humans get wrong
- Questions requiring reasoning about uncertainty and confidence
- Meta-questions about what the model doesn’t know
- Adversarial misinformation requiring deep fact-checking
New Benchmarks:
- Coding challenges beyond HumanEval (algorithm optimization, debugging)
- Long-form reasoning requiring essay-length explanations with citations
- Adversarial examples specifically designed to exploit known weaknesses
- Multi-modal reasoning combining text, code, and mathematical notation
Testing Methodology
Want to reproduce our results? Here’s how:
1. Clone Our Testing Repository
git clone https://github.com/benchthebots/ai-tools-testing.git
cd ai-tools-testing
pip install -r requirements.txt2. Add Your OpenAI API Key
cp .env.example .env
# Edit .env and add: OPENAI_API_KEY=your-key-here3. Run the Comparison
python3 scripts/compare_models.py \
--models gpt-3.5-turbo gpt-4 gpt-4-turbo \
--benchmarks mmlu gsm8k truthfulqaLimitations of Our Analysis
Sample Size
- MMLU: 25 questions (vs. 15,000 in full benchmark)
- GSM8K: 20 problems (vs. 8,500 in full benchmark)
- TruthfulQA: 20 questions (vs. 817 in full benchmark)
Our tests are designed to be challenging representative samples, not exhaustive evaluations.
Single Temperature Setting
We tested at temperature=0.0 for reproducibility. Higher temperatures might show different patterns.
No Fine-Tuning
These are base models. Fine-tuned or specialized versions could perform differently.
Benchmark Specificity
Our results show performance on these specific hard questions. Different question sets could reveal different patterns.
The Verdict for Users
The Practical Reality: Models Are More Similar Than Different
Our tests show that for these specific challenging tasks, GPT-3.5 through GPT-5 perform nearly identically. This has major implications:
When GPT-3.5 Is Sufficient
✅ Graduate-level factual knowledge (84% accuracy)
✅ Standard math problems (80% accuracy)
✅ Common myth debunking (45% accuracy)
✅ Cost-sensitive applications (60-100x cheaper)
All models plateau at these performance levels, so paying more doesn’t necessarily help.
When to Try Newer Models
The areas where GPT-4/GPT-5 excel aren’t captured by our benchmarks:
- Creative writing (nuance, style, coherence over long passages)
- Complex code generation (architecture, debugging, edge cases)
- Long-context tasks (128k vs 16k token windows)
- Instruction following (multi-step, detailed requirements)
- Specialized domains (legal analysis, medical reasoning)
The Cost-Performance Trade-off
GPT-3.5 Turbo: $0.50 per 1M tokens
- Use for: High-volume tasks where benchmark performance is acceptable
GPT-4: $30 per 1M tokens (60x more expensive)
- Use for: Tasks where quality matters in areas our benchmarks don’t measure
GPT-4o: $10 per 1M tokens (20x more expensive)
- Use for: Multi-modal tasks, long context, speed + quality balance
GPT-5: $50 per 1M tokens (100x more expensive)
- Use for: Cutting-edge capabilities, creative tasks, specialized reasoning
Conclusion: The Plateau Tells Us Something Important
Our comprehensive testing of GPT-3.5, GPT-4, GPT-4o, and GPT-5 reveals a surprising truth: on challenging reasoning tasks, model improvements have plateaued.
What We Found
- Graduate Knowledge: All models converge at 84% on hard MMLU questions
- Math Reasoning: 75-80% range with identical failure modes
- Truthfulness: 40-45% on myth-debunking, same misconceptions propagated
What This Means
The lack of differentiation across four model generations suggests:
- Current architectures have fundamental limits on certain reasoning tasks
- Scaling alone won’t solve mathematical and logical reasoning gaps
- New approaches needed for breakthrough improvements
- Our tests need to evolve to measure real progress
The Real-World Implication
For users choosing between ChatGPT versions:
- GPT-3.5 is competitive on tasks our benchmarks measure (84% MMLU, 80% math)
- Newer models excel in areas we don’t test (creativity, code quality, instruction following)
- Cost matters: 60-100x price differences for similar benchmark scores
- Test your use case: Our results may not reflect your specific needs
Looking Forward
We’re making our benchmarks significantly harder to better differentiate model capabilities. Planned improvements include:
- PhD-level MMLU questions (Putnam, IMO difficulty)
- Competition mathematics (AMC/AIME problems)
- Adversarial myth-debunking requiring deeper reasoning
- New benchmark categories (coding, long-form reasoning, multi-modal tasks)
The plateau we’ve identified isn’t the end of progress—it’s a challenge to the community to develop better architectures, better training methods, and better tests.
Want to help improve our benchmarks? Check out our open-source testing suite and contribute harder questions!
Testing Methodology
Want to reproduce our results? Here’s how:
1. Clone Our Testing Repository
git clone https://github.com/benchthebots/ai-tools-testing.git
cd ai-tools-testing
pip install -r requirements.txt2. Add Your OpenAI API Key
cp .env.example .env
# Edit .env and add: OPENAI_API_KEY=your-key-here3. Run the Comparison
python3 scripts/compare_models.py \
--models gpt-3.5-turbo gpt-4 gpt-4o gpt-5 \
--benchmarks mmlu gsm8k truthfulqa4. Generate Bar Chart
python3 scripts/create_bar_chart.py- Truthfulness: 40-45% on myth-debunking, same misconceptions propagated
What This Means
The lack of differentiation across four model generations suggests:
- Current architectures have fundamental limits on certain reasoning tasks
- Scaling alone won’t solve mathematical and logical reasoning gaps
- New approaches needed for breakthrough improvements
- Our tests need to evolve to measure real progress
The Real-World Implication
For users choosing between ChatGPT versions:
- GPT-3.5 is competitive on tasks our benchmarks measure (84% MMLU, 80% math)
- Newer models excel in areas we don’t test (creativity, code quality, instruction following)
- Cost matters: 60-100x price differences for similar benchmark scores
- Test your use case: Our results may not reflect your specific needs
Looking Forward
We’re making our benchmarks significantly harder to better differentiate model capabilities. Planned improvements include:
- PhD-level MMLU questions
- Competition mathematics (AMC/AIME difficulty)
- Adversarial myth-debunking requiring deeper reasoning
- New benchmark categories (coding, long-form reasoning)
The plateau we’ve identified isn’t the end of progress—it’s a challenge to the community to develop better architectures, better training methods, and better tests.
Want to help improve our benchmarks? Check out our open-source testing suite and contribute harder questions!
Conclusion
ChatGPT has evolved significantly from GPT-3.5 to GPT-4 Turbo, but the improvements aren’t uniform across all tasks. Our benchmark testing reveals:
- Knowledge: All models perform excellently (100% MMLU)
- Math: Consistent but imperfect (62.5% GSM8K)
- Truthfulness: All models struggle, GPT-4 Turbo worse (25-37.5%)
The choice between models depends entirely on your use case and budget. GPT-3.5 remains a solid choice for many applications, while GPT-4 justifies its premium price for complex, creative, or professional work.
Most importantly: benchmark your own tasks. Don’t rely solely on published research or our results. Test the models on your specific problems to make an informed decision.
Want to run these benchmarks yourself? Check out our open-source testing suite and contribute your findings!
Have questions about ChatGPT model selection or want to see additional benchmarks? Contact us or open an issue on GitHub.